Connect Marmot to Claude Desktop

Half the company already has Claude Desktop installed. That's a direct line to your data catalog sitting idle on every laptop. Hook it up to Marmot over MCP, which is one config file, and everyone who has Claude open can ask about your data the same way they ask about anything else. This post walks through the setup end to end.
Why Claude Desktop
Most questions about data come from people who didn't catalog it. Which table holds subscription revenue, what "active user" actually means in the dashboard they're quoting, who owns the pipeline they're about to build on. In practice those questions land in a Slack channel and sit there until someone from the data team has a minute.
With Marmot connected to Claude Desktop, people can just ask. "What data do we have on orders?" or "who owns the payments topic?" gets answered from the catalog, with the actual schema and the actual owner. The person asking keeps working instead of waiting, and the data team stops being a routing layer for questions the catalog already answers.
It's also another return on the cataloging work. The same descriptions, owners and glossary terms people browse in the Marmot UI now also answer questions in Claude, right in the middle of whatever someone is working on. They ask mid-task, get the answer, and carry on.
Prerequisites
You need two things:
- A running Marmot instance. If you haven't deployed one yet, follow the deployment docs; there are guides for Docker, Kubernetes via the official Helm chart, and more.
- Claude Desktop, available from claude.com/download.
You'll also need a Marmot API key for Claude to authenticate with. In Marmot, go to your Profile, then API Keys, and generate a new key. Claude gets the same permissions as your user account, so all role-based access controls still apply.
Configure Claude Desktop
Open Claude Desktop and go to Settings → Developer:
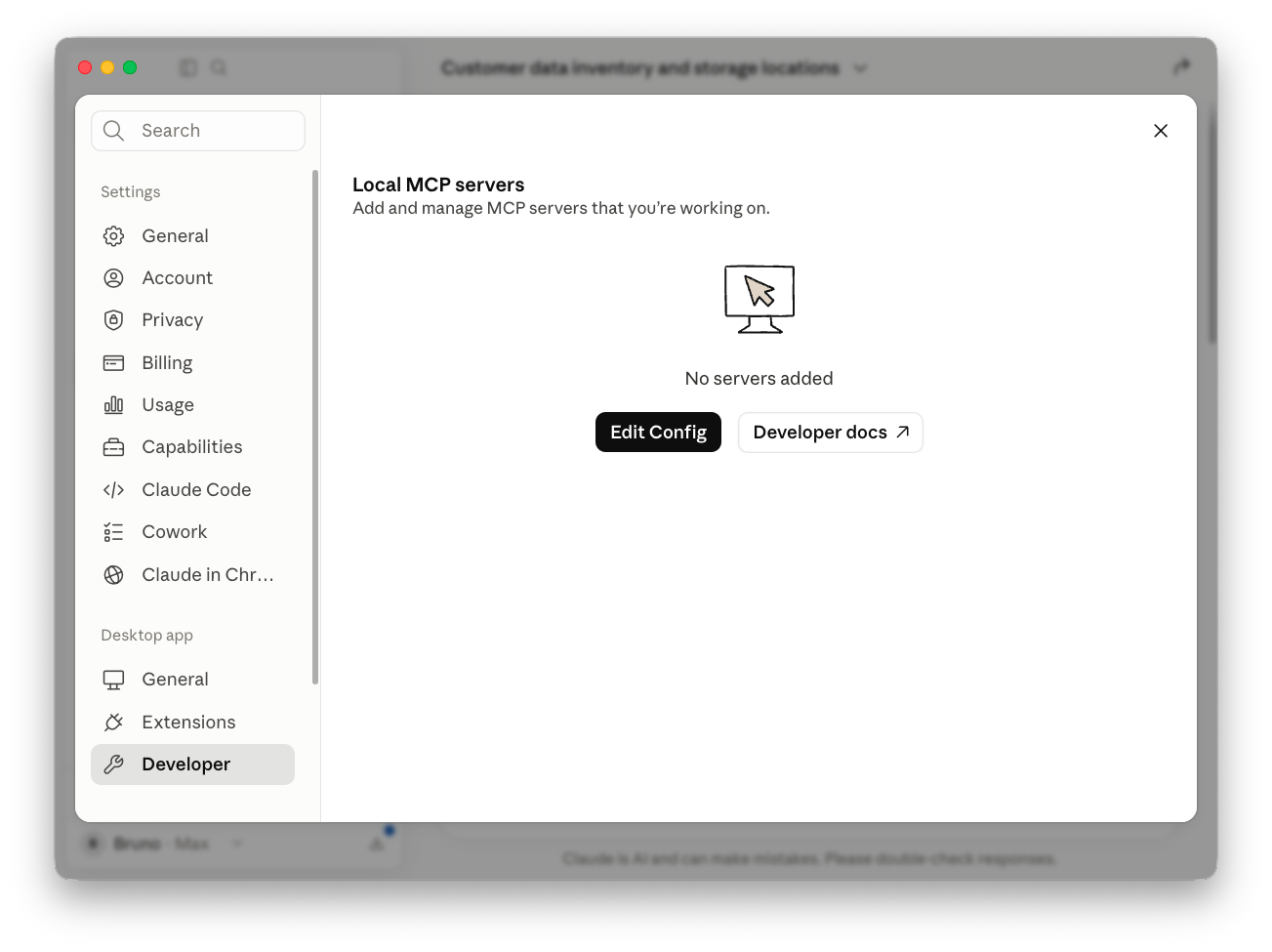
Click Edit Config. This opens claude_desktop_config.json, which lives at:
- macOS:
~/Library/Application Support/Claude/claude_desktop_config.json - Windows:
%APPDATA%\Claude\claude_desktop_config.json - Linux:
~/.config/Claude/claude_desktop_config.json
Add Marmot under mcpServers. Claude Desktop speaks to local MCP servers, so we use mcp-remote to bridge to Marmot's built-in MCP endpoint:
{
...
"mcpServers": {
"marmot": {
"command": "npx",
"args": [
"-y",
"mcp-remote",
"http://localhost:8080/api/v1/mcp",
"--header",
"X-API-Key:<your-api-key>",
"--allow-http"
]
}
},
...
}
Replace <your-api-key> with the API key you generated earlier, and the URL with wherever your Marmot instance runs. The endpoint is always /api/v1/mcp on your Marmot host.
Only add --allow-http if your Marmot host uses plain HTTP, like the localhost example above. If your instance is served over HTTPS, use the https:// URL and drop the flag.
Save the file and restart Claude Desktop. Marmot now shows up as a connected server under Settings → Developer, and Claude has the catalog's tools available: data discovery, ownership lookups, lineage tracing and glossary definitions.
Make sure there's something to find
Claude can only surface what's in the catalog, so if your Marmot instance is still empty, populate it first. The easiest way is straight from the Marmot UI: go to Runs, click Create Pipeline and pick the plugin for a source you already have, whether that's PostgreSQL, BigQuery, Kafka, S3 or anything else. The pipeline discovers and catalogs your assets automatically. The UI guide walks through each step.
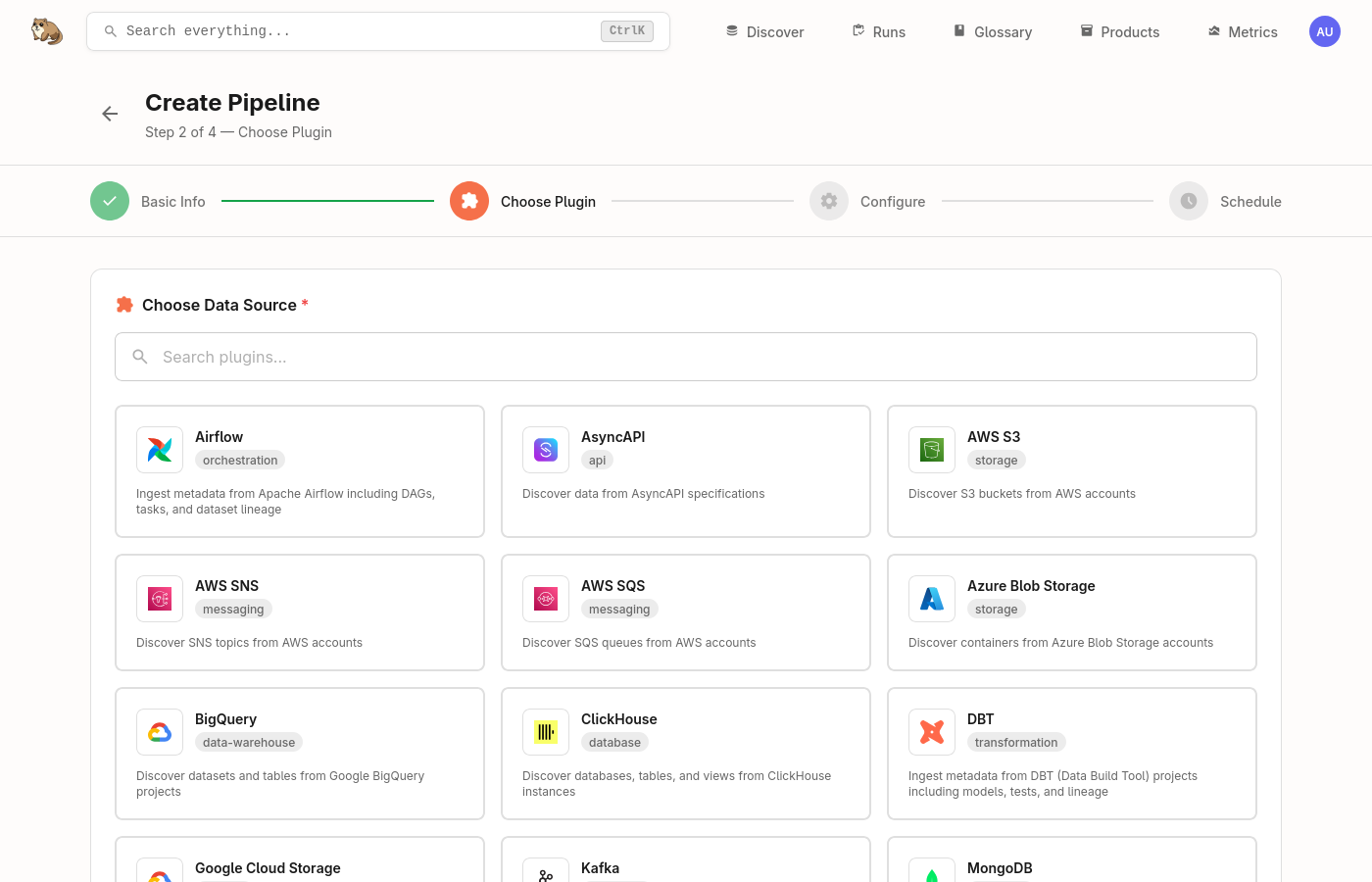

If you'd rather do it as code, the Populating docs cover the CLI, Terraform, Pulumi and the REST API. One source is plenty to follow along with the rest of this post.
Ask your catalog anything
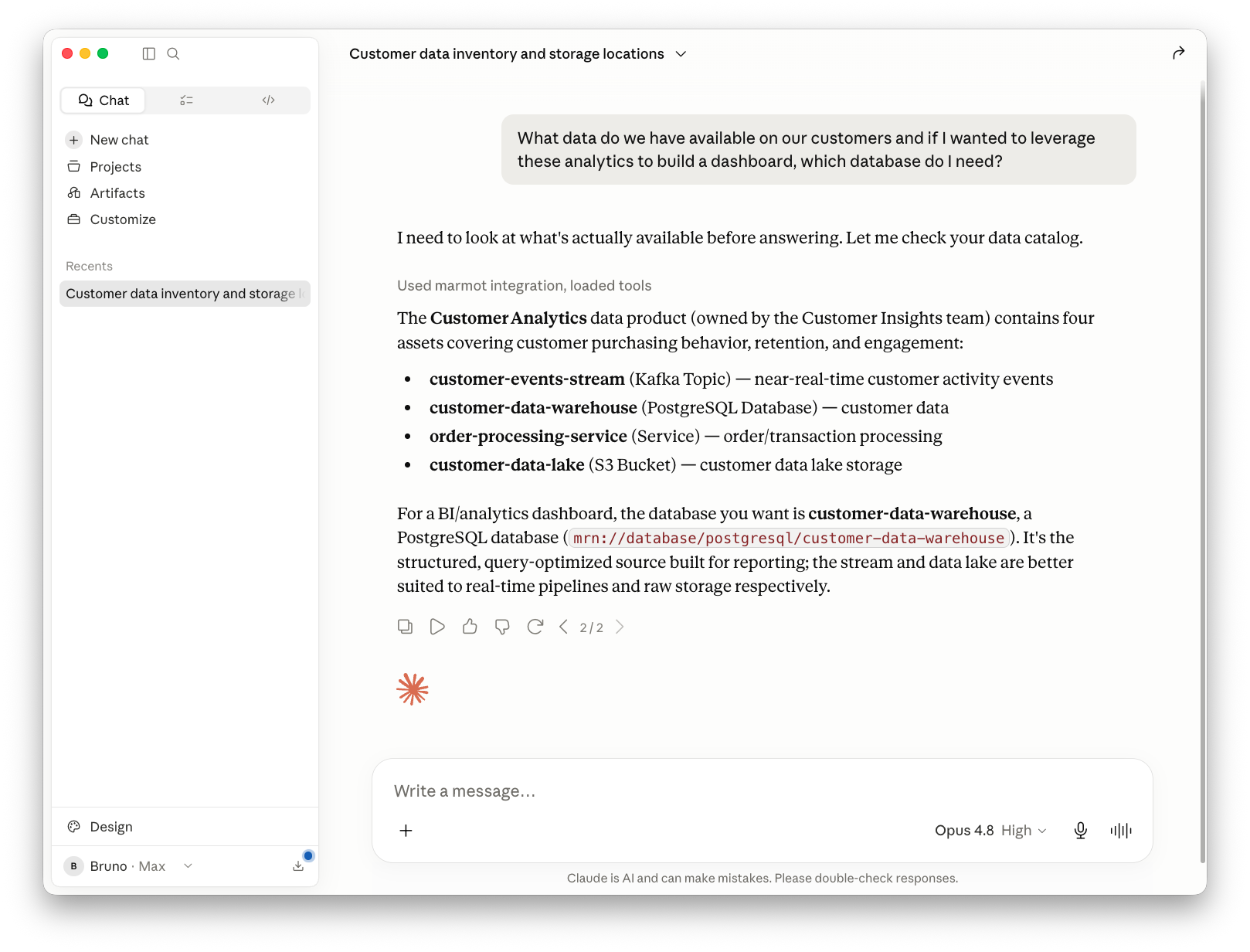
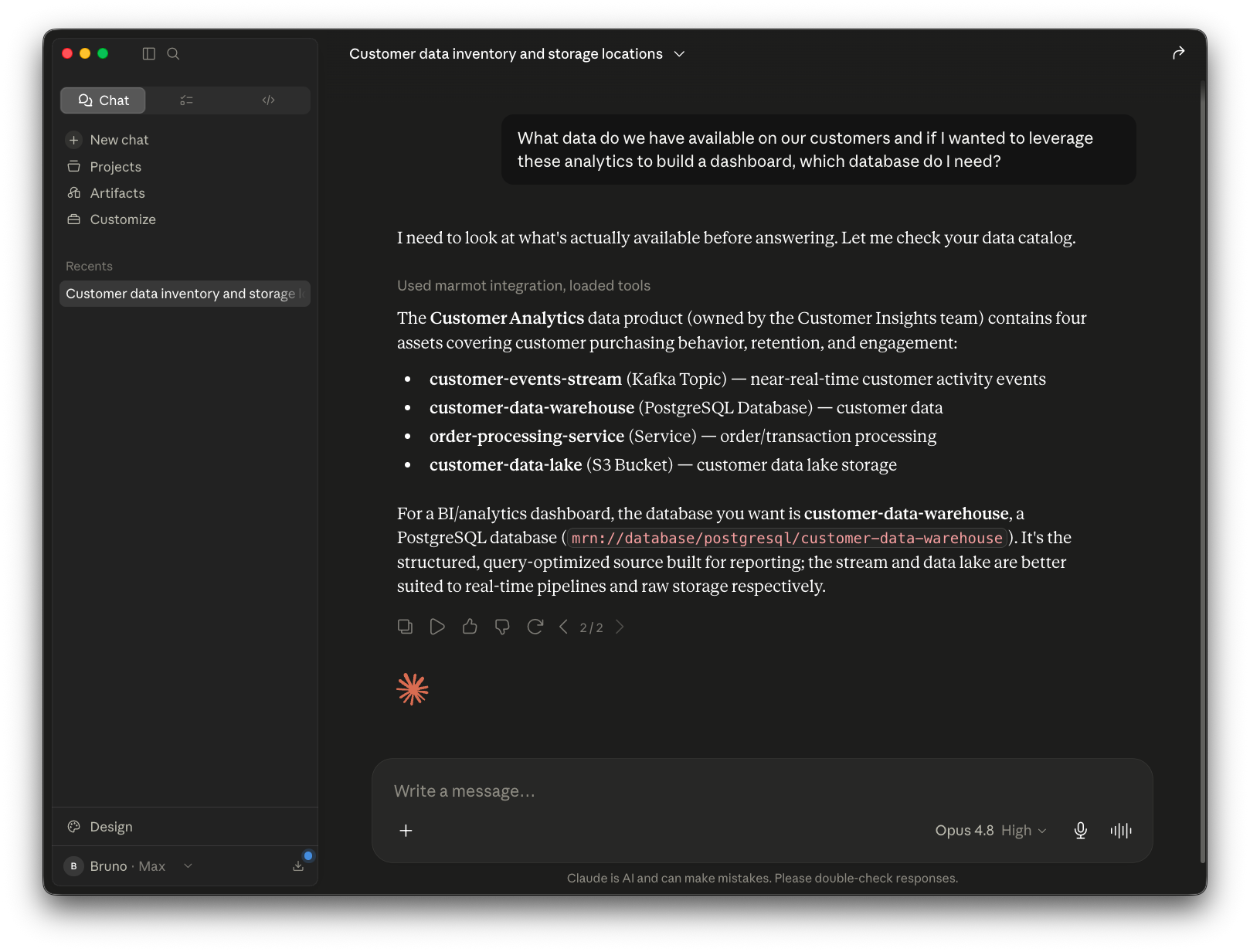
Now you can start asking questions in plain language. Here I asked what data we have available on our customers, and which database I'd need if I wanted to build a dashboard on those analytics:
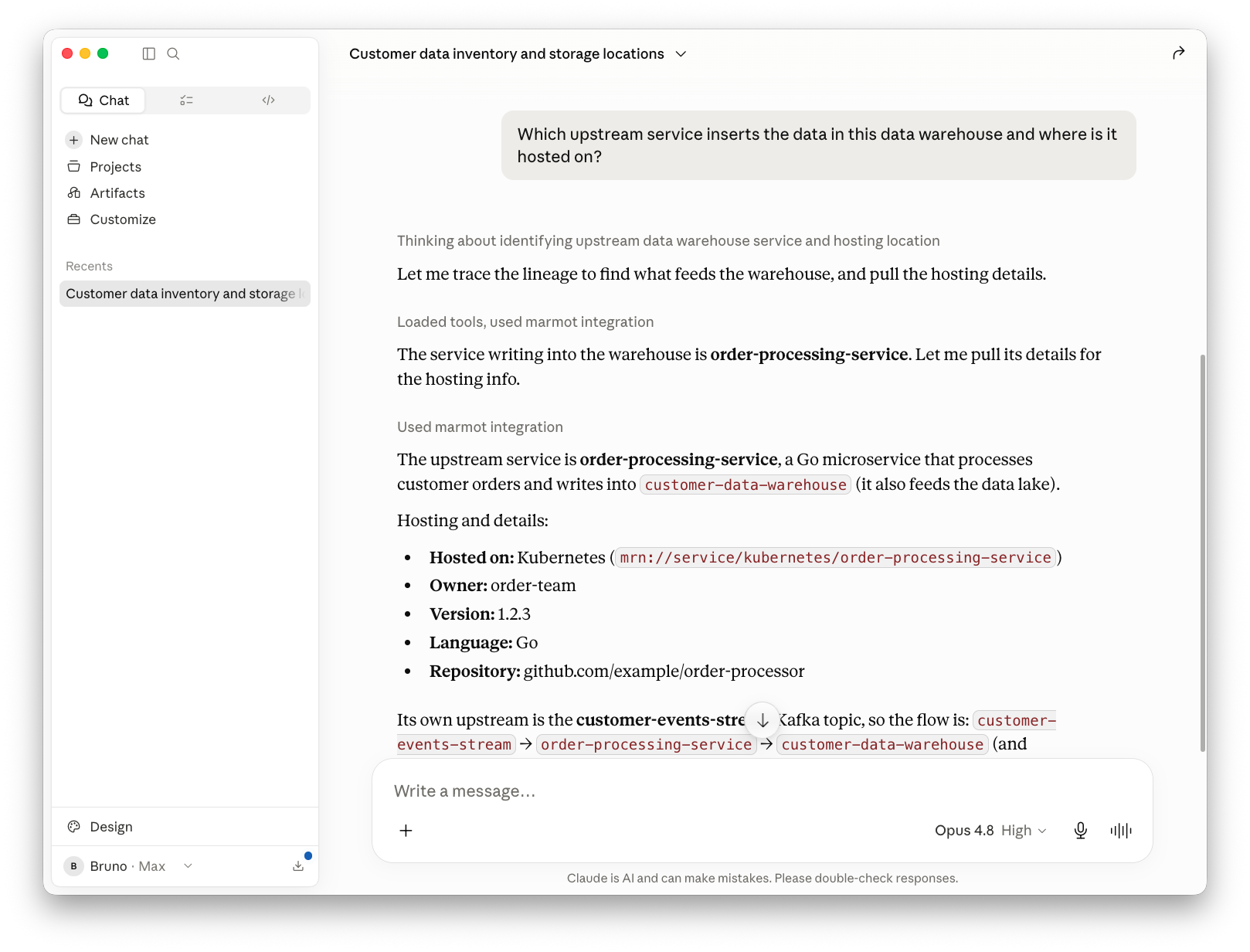
Lineage works the same way. Here I asked which upstream service inserts the data into the warehouse, and where that service is hosted:
This is what a context layer like Marmot buys you. All of that knowledge already existed somewhere in the company, scattered across tools, wikis and people's heads. Asking around on Slack and digging through docs carried us for years, but it's slow and it depends on the right person having time. With a context layer you get the same answers on your own, in seconds.
Where to go next
- Descriptions, owners and glossary terms are what Claude actually answers with, so fill those in for the assets people ask about most.
- Everyone on the team connects with their own API key. Permissions follow the user, so nobody sees more through Claude than they would in Marmot itself.
- The same endpoint works from Claude Code, Cursor and any other MCP client; the MCP docs have the config for each.
Join the Community
Get help, share feedback and connect with other Marmot users on Discord.
Join Discord